Introduction
Building interoperable clinical genomics infrastructure for precision medicine
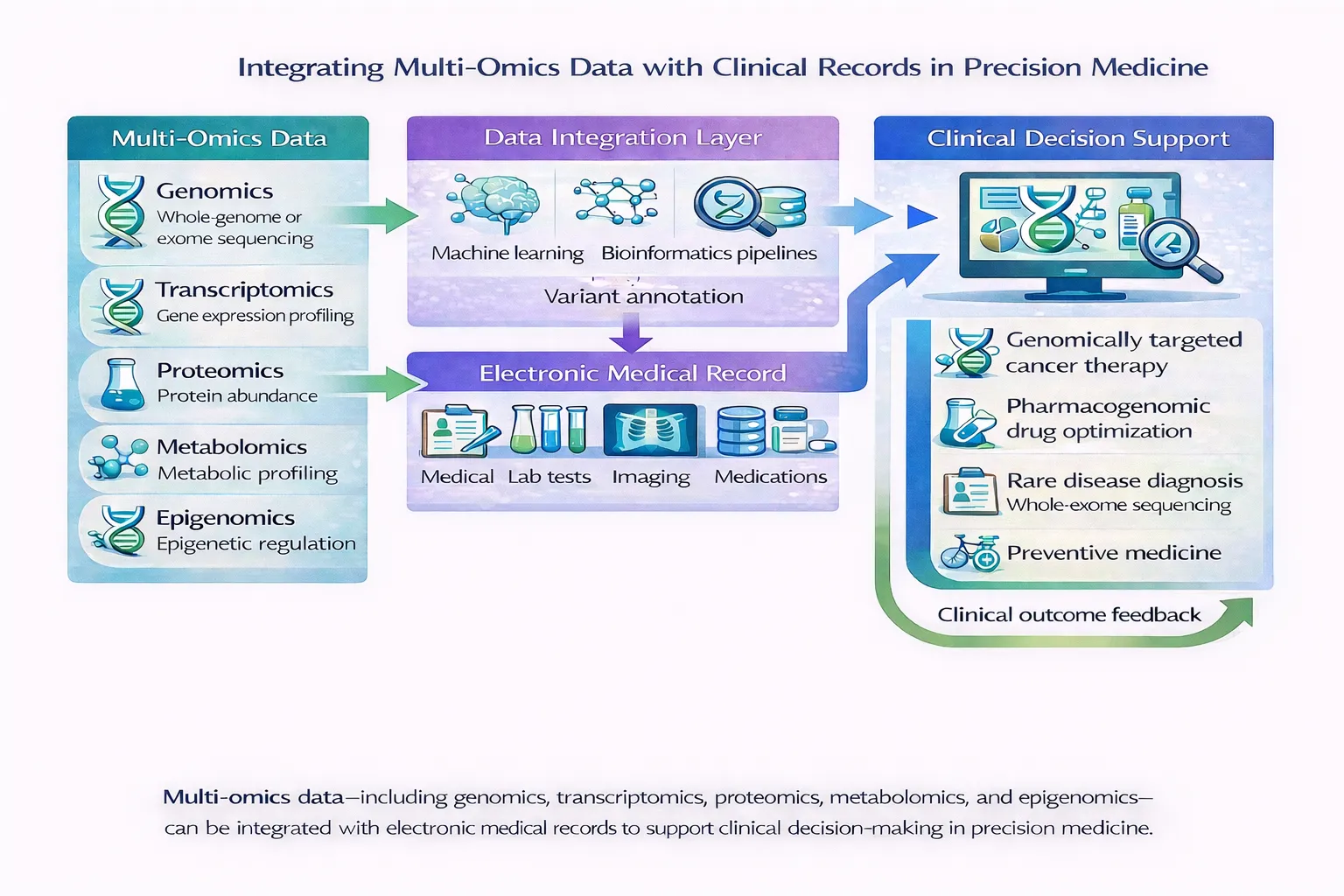
The integration of genomic data into electronic health records (EHRs) has become one of the defining challenges in precision medicine. Over the past decade, advances in sequencing technologies have dramatically reduced the cost and turnaround time of genomic testing, enabling widespread use of germline sequencing, somatic profiling, pharmacogenomics, carrier screening, and polygenic risk assessment across clinical practice. Yet despite the rapid growth of genomic data generation, healthcare systems continue to struggle with how to incorporate this information into routine clinical workflows in a scalable, computable, and interoperable manner.
Historically, genomic results were often delivered as static PDF reports attached to the EHR. While suitable for human reading, these reports are poorly suited for computational querying, longitudinal reinterpretation, clinical decision support, or large-scale analytics. The emergence of interoperability standards such as HL7 FHIR (Fast Healthcare Interoperability Resources) has begun to address this problem by enabling structured, machine-readable genomic data exchange between laboratories, genomic repositories, clinical applications, and healthcare systems.
Based on the publications “The interface of genomic information with the electronic health record: a points to consider statement of the American College of Medical Genetics and Genomics (ACMG)” and “Introducing HL7 FHIR Genomics Operations: a developer-friendly approach to genomics-EHR integration”, this article explores the technical foundations, architectural principles, interoperability standards, and implementation challenges underlying modern genomics–EHR integration.
Why Genomics–EHR Integration Matters
Modern genomic medicine depends not only on sequencing technologies but also on the ability to deliver clinically actionable genomic insights at the point of care. Sequencing data alone has limited clinical value if it cannot be interpreted, updated, searched, or integrated into physician workflows.
Unlike conventional laboratory tests, genomic data presents several unique challenges:
- The volume of data is extremely large
- Variant interpretation evolves over time
- Clinical significance may change as knowledge expands
- Many variants are probabilistic rather than deterministic
- Genomic information may remain relevant throughout a patient’s lifetime
- Data often originates from external laboratories using heterogeneous formats
These characteristics fundamentally differ from conventional laboratory values such as electrolytes or blood counts. As a result, genomics requires more sophisticated interoperability infrastructure than traditional health data exchange.
The ACMG points-to-consider statement emphasizes that genomic information should not simply be stored as static reports, but instead integrated in ways that support longitudinal management, reinterpretation, clinical decision support, and future scalability. ([Nature][1])
The Evolution of Clinical Genomics Data Exchange
Early clinical genomics workflows largely relied on laboratory-generated PDFs inserted into EHR systems. This approach was simple to implement but introduced major limitations:
- Genomic findings could not easily be queried computationally
- Clinical decision support systems could not access variant-level data
- Variant reinterpretation was difficult to operationalize
- Pharmacogenomic alerts could not dynamically update
- Data sharing across institutions was limited
As next-generation sequencing expanded from single-gene testing to exome and genome sequencing, these limitations became increasingly problematic.
At the same time, genomic testing itself became more complex. Clinical reports began including:
- Single nucleotide variants
- Structural variants
- Copy-number changes
- Pharmacogenomic haplotypes
- Tumor mutational signatures
- Polygenic risk scores
- Secondary findings
Managing this diversity required interoperable standards capable of representing genomic concepts computationally.
HL7 FHIR: A New Foundation for Interoperability
HL7 Fast Healthcare Interoperability Resources (FHIR) 🔗 emerged as a next-generation interoperability standard designed to simplify healthcare data exchange using modern web technologies and RESTful APIs.
FHIR differs from earlier interoperability standards by emphasizing:
- Modular resources
- API-based architecture
- Web-native communication models
- Extensibility
- Lightweight implementation
FHIR organizes healthcare data into reusable “resources,” such as:
- Patient
- Observation
- Condition
- Medication
- DiagnosticReport
These resources can be linked together to represent complex clinical relationships.
HL7 FHIR gained rapid international adoption because it aligned healthcare interoperability with contemporary internet application development paradigms. This made it significantly easier for developers to build interoperable healthcare applications.
For genomics, this flexibility was particularly important because genomic data structures are highly heterogeneous and evolve rapidly over time.
The HL7 FHIR Genomics Standard
To address genomic-specific interoperability needs, HL7 developed the FHIR Genomics Reporting Implementation Guide, which defines standardized representations for genomic findings within FHIR.
The standard supports representation of:
- Germline variants
- Somatic variants
- Structural rearrangements
- Haplotypes and star alleles
- Pharmacogenomic findings
- HLA typing
- Diagnostic interpretations
Importantly, the standard enables genomic data to become computable rather than merely document-based.
For example, instead of storing a BRCA1 pathogenic variant inside a PDF, the variant can be represented as structured data linked to:
- Genomic coordinates
- Transcript annotations
- Clinical significance
- Associated diseases
- Therapeutic implications
This enables downstream applications to perform automated reasoning, querying, filtering, and decision support.
The JAMIA paper notes that HL7 FHIR Genomics was designed not merely for data transport, but also to normalize heterogeneous genomic representations across institutions and vendors.
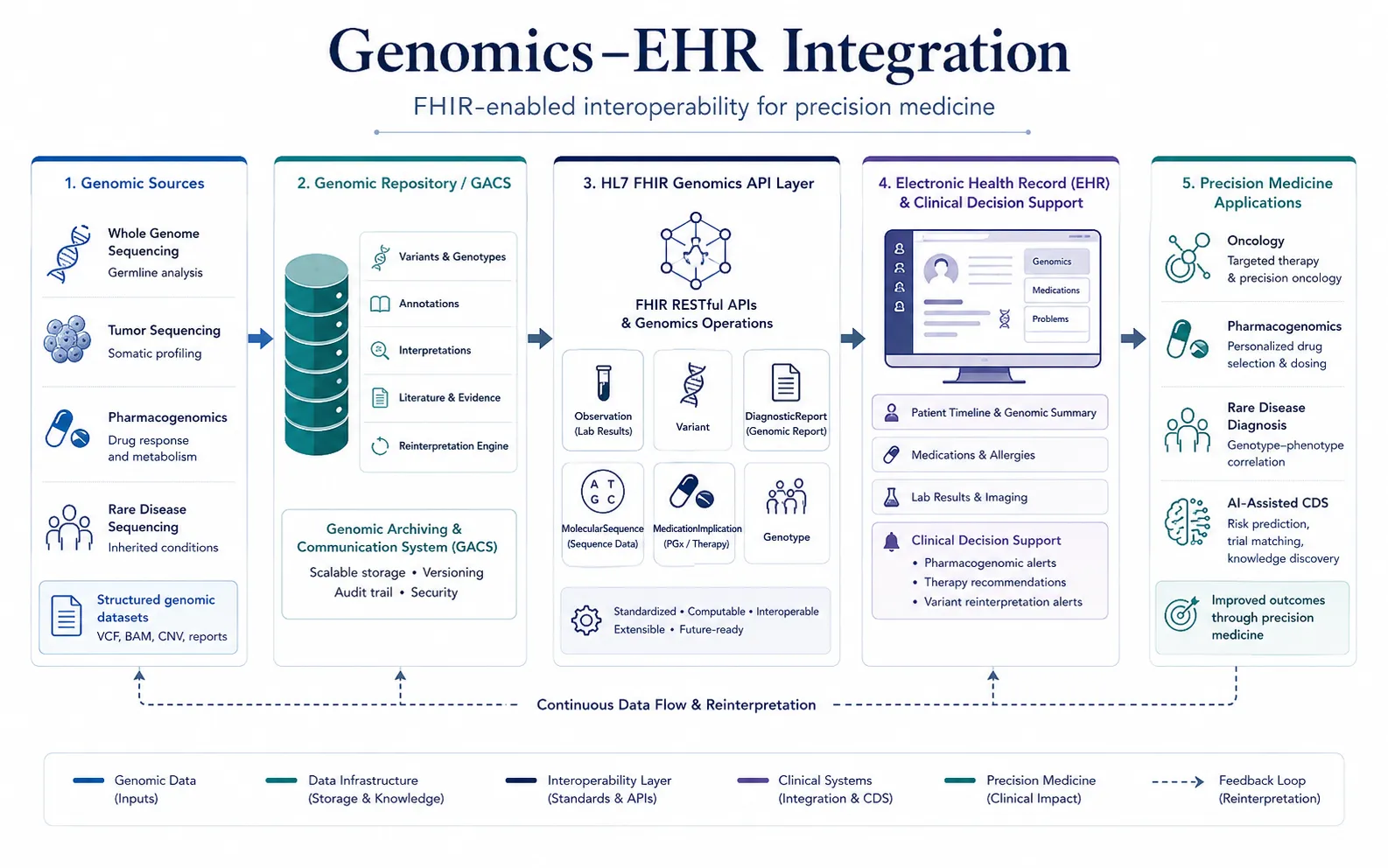
Genomics Operations: Moving Beyond Static Data Exchange
One of the central concepts introduced in the space of EHR and genomics integration is the use of FHIR Genomics Operations.
Traditional FHIR search capabilities are often insufficient for genomics because genomic datasets are extraordinarily large and computationally complex. Variant interpretation may require querying millions of records, aggregating annotations, or dynamically filtering findings based on phenotype or clinical context.
FHIR Genomics Operations extend standard FHIR APIs by enabling server-side processing and abstraction layers that simplify genomic application development. The FHIR Genomics Implementation Guide 🔗 describes these operations as effectively “wrapping” a genomic repository and presenting a normalized interface to applications.
This architecture offers several advantages:
- Developers do not need to understand raw genomic file formats
- Bioinformatic complexity is encapsulated within the server
- Different repositories can expose consistent APIs
- Applications can remain lightweight and interoperable
The authors developed fifteen genomics operations supporting use cases such as:
- Variant discovery
- Clinical trial matching
- Pharmacogenomic screening
- Hereditary disease assessment
- Variant reinterpretation
This operational model represents a major conceptual shift from document-centric genomics toward API-driven precision medicine infrastructure.
Genomic Archiving and Communication Systems (GACS)
Because genomic datasets are extremely large and continually evolving, many institutions avoid storing full genomic datasets directly inside the EHR itself.
Instead, genomic information may reside in external systems called Genomic Archiving and Communication Systems (GACS).
In this architecture:
Sequencing Lab → Genomic Repository (GACS) → FHIR API Layer → EHR ApplicationsThe EHR stores clinically relevant summaries and references, while the genomic repository retains the underlying high-dimensional molecular data.
FHIR Genomics Operations provide the interoperability layer connecting these systems.
This separation offers several advantages:
- Scalability for large genomic datasets
- Independent updating of variant knowledge
- Reduced EHR storage burden
- Improved computational performance
- Easier integration of future omics modalities
This architecture is especially important because genomic interpretation changes continuously as scientific knowledge evolves.
Challenges in Genomics–EHR Integration
Despite substantial progress, several technical and clinical challenges remain unresolved.
Data Complexity
Next-generation sequencing can generate millions of variants per patient. Most variants are clinically irrelevant, but distinguishing clinically actionable findings requires extensive annotation pipelines and interpretation frameworks.
Additionally, genomic data includes diverse variant types:
- SNVs
- Indels
- Structural variants
- Repeat expansions
- Copy-number changes
- Gene fusions
Representing all these consistently remains difficult.
Dynamic Interpretation
Unlike conventional laboratory values, genomic interpretation evolves over time.
A variant previously classified as uncertain significance may later become pathogenic or benign as new evidence emerges.
This creates a need for:
- Reanalysis pipelines
- Longitudinal reinterpretation workflows
- Dynamic clinical decision support
The ACMG paper stresses that genomic data should therefore be treated as a long-term clinical asset rather than a static laboratory result. ([Nature][1])
Clinical Workflow Integration
Even when structured genomic data exists, integrating it into clinician workflows remains challenging.
Clinicians need:
- Context-specific interpretation
- Actionable summaries
- Pharmacogenomic alerts
- Therapy guidance
- Risk stratification tools
Raw genomic data alone is insufficient for clinical adoption.
FHIR-based CDS systems aim to bridge this gap by enabling real-time genomic decision support.
Standardization and Semantic Interoperability
Different laboratories may represent the same variant differently.
Differences can occur in:
- Nomenclature
- Reference transcripts
- Coordinate systems
- Interpretation frameworks
- Phenotype ontologies
Achieving semantic interoperability therefore requires harmonized standards beyond simple data transport.
Clinical Decision Support and Precision Medicine
One of the most important applications of genomics–EHR integration is clinical decision support (CDS).
FHIR-enabled genomic CDS systems can support:
- Pharmacogenomic prescribing alerts
- Cancer therapy recommendations
- Hereditary cancer screening
- Variant reinterpretation notifications
- Clinical trial matching
For example, a pharmacogenomic CDS engine could automatically detect a CYP2C19 variant affecting clopidogrel metabolism and generate prescribing guidance at the point of care. Similarly, oncology applications could identify actionable tumor variants linked to targeted therapies or ongoing trials.
Standardized APIs dramatically lower barriers for precision medicine application development by abstracting away underlying bioinformatic complexity.
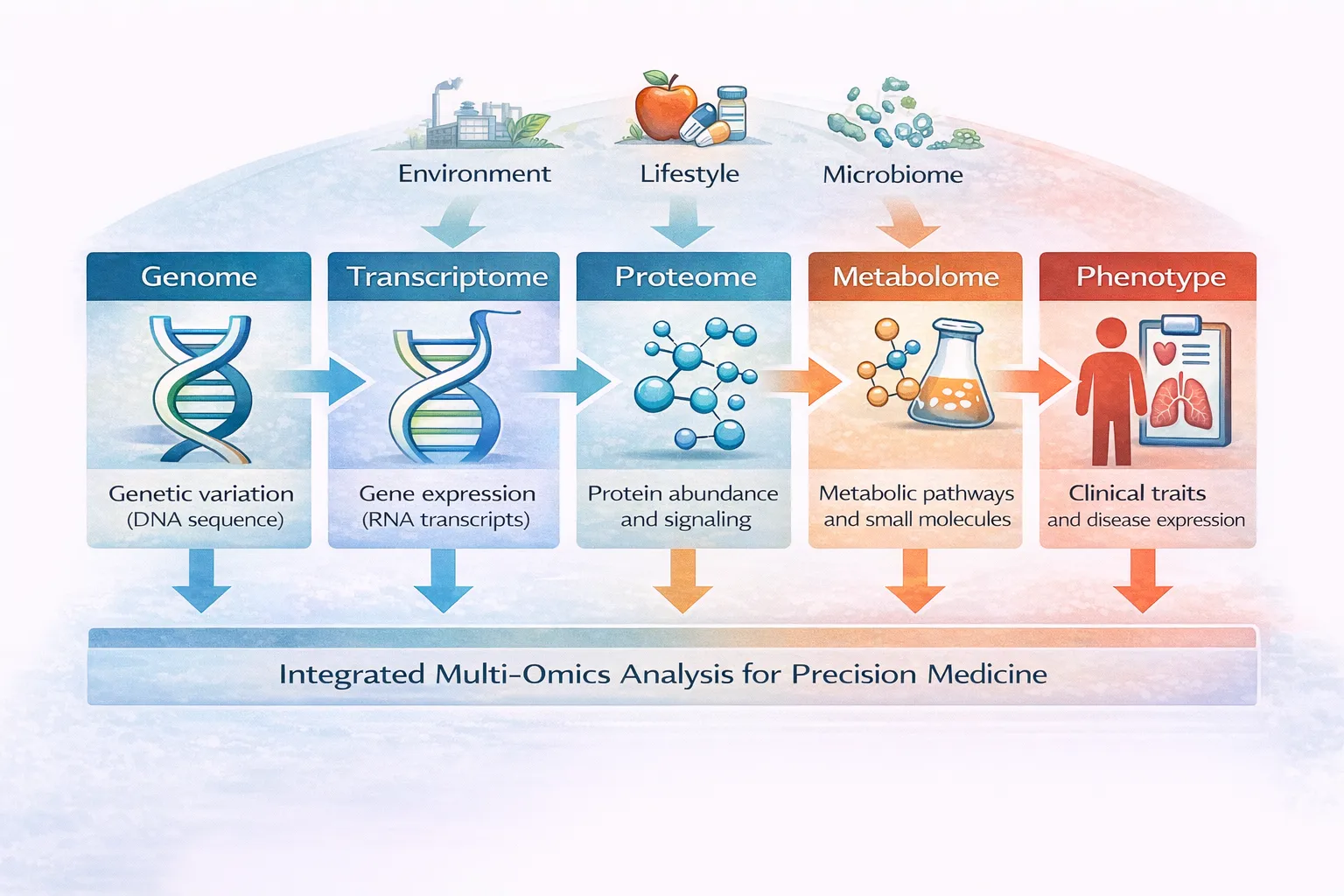
The Future of Genomics Interoperability
Genomics–EHR integration is still in an early phase of maturation. Future developments are likely to include:
- Real-time genomic CDS
- Polygenic risk integration
- Multi-omics interoperability
- Federated genomic repositories
- AI-assisted interpretation systems
- Longitudinal genomic monitoring
As sequencing becomes increasingly routine, genomic interoperability infrastructure may become foundational to healthcare systems rather than specialized research functionality.
FHIR-based ecosystems are particularly important because they allow genomics to integrate with broader digital health infrastructures including:
- Clinical workflows
- Imaging systems
- Laboratory systems
- Research platforms
- Population health analytics
The convergence of interoperability standards, scalable APIs, and precision medicine applications may ultimately enable genomic medicine to function as a continuously updated component of longitudinal clinical care.
Conclusion
Genomics–EHR integration represents one of the central infrastructure challenges in precision medicine. Sequencing technologies alone cannot transform healthcare unless genomic information becomes interoperable, computable, longitudinally manageable, and clinically actionable.
HL7 FHIR and related genomics standards provide a framework for moving beyond static PDF reports toward scalable, API-driven precision medicine ecosystems. By enabling standardized genomic representations, interoperable operations, and modular application development, FHIR-based architectures are reshaping how genomic data can be incorporated into clinical care.
The transition from document-based genomics to computable genomic medicine will likely play a foundational role in the future of precision healthcare, enabling more dynamic clinical decision support, scalable multi-omics integration, and personalized treatment strategies across medicine.
Explore Related Insights
- Integrating Genomics into Multimodal EHR Foundation Models
- The Role of Electronic Health Records in Precision Medicine
- Deep Learning for Multi-Omics Data Integration
- Cross-Modality Integration in Precision Medicine: AI, Multi-Omics & EHR